














лЎңмҠӨнҠём•„нҒ¬ нҷ”м ң 집мӨ‘
- лҰ¬нҸ¬н„° лүҙмҠӨ
- лЎңмҠӨнҠём•„нҒ¬ мҶҢмӢқ
- нҢҒкіј л…ён•ҳмҡ° кІҢмӢңнҢҗ
- в”” мӮӯм ңлҗң нҢҒ кІҢмӢңнҢҗ
- кҙҖлҰ¬мһҗ мқёмҰқ кІҢмӢңл¬ј
лҜёл””м–ҙ кІҢмӢңнҢҗ
- лЎңм•„ мң нҠңлёҢ лӘЁм•„ліҙкё°
- нҢ¬м•„нҠё / м№ҙнҲ° к°Өлҹ¬лҰ¬
- лЎңм•„ мқёлІӨ мҳҒмғҒ лӘЁмқҢ
- мҠӨнҒ¬лҰ°мғ· к°Өлҹ¬лҰ¬
- в”” м»ӨмҠӨн„°л§Ҳмқҙ징 мһҗлһ‘
- в”” м»Өл§Ҳ мғҒмӢң кіөмң
- в”” лЎңм•„ AI к·ёлҰј
- лЎңмҠӨнҠём•„нҒ¬ мҳҒмғҒкҙҖ
м»Өл®ӨлӢҲнӢ° кІҢмӢңнҢҗ
- лЎңм•„ нӢ°м–ҙлһӯнӮ№
- мһҗмң кІҢмӢңнҢҗ
- в”” мҳӨлҠҳмқҳ 30추кёҖ
- в”” мҳӨлҠҳмқҳ 10추кёҖ
- мҠӨнҶ лҰ¬ кІҢмӢңнҢҗ
- м§Ҳл¬ёкіј лӢөліҖ
- PVP л°ёлҹ°мҠӨ нҶ лЎ
- м„ңлІ„ мӮ¬кұҙ/мӮ¬кі кІҢмӢңнҢҗ
- мқҙмҠҲ/нҶ лЎ /лІ„к·ё м ңліҙ
- кёёл“ң лӘЁм§‘ кІҢмӢңнҢҗ
- л Ҳмқҙл“ң нҢҢнӢ°м°ҫкё°
- лЎңмҠӨнҠём•„нҒ¬м—җ л°”лһҖлӢӨ
- мғқнҷң м •ліҙ кіөмң кІҢмӢңнҢҗ
- л°©мҶЎ л°Ҹ нҷҚліҙ кІҢмӢңнҢҗ
- мӮ¬мқҙнҠё кұҙмқҳ/м ңліҙ
м§Ғм—… кІҢмӢңнҢҗ
- л””мҠӨнҠёлЎңмқҙм–ҙ
- мӣҢлЎңл“ң
- лІ„м„ңм»Ө
- нҷҖлҰ¬лӮҳмқҙнҠё
- мҠ¬л Ҳмқҙм–ҙ
- л°°нӢҖл§ҲмҠӨн„°
- мқёнҢҢмқҙн„°
- кё°кіөмӮ¬
- м°ҪмҲ мӮ¬
- мҠӨнҠёлқјмқҙм»Ө
- лёҢл Ҳмқҙм»Ө
- лҚ°л№Ңн—Ңн„°
- лё”лһҳмҠӨн„°
- нҳёнҒ¬м•„мқҙ
- мҠӨм№ҙмҡ°н„°
- кұҙмҠ¬л§Ғм–ҙ
- л°”л“ң
- м„ңлЁёл„Ҳ
- м•„лҘҙм№ҙлӮҳ
- мҶҢм„ңлҰ¬мҠӨ
- лё”л Ҳмқҙл“ң
- лҚ°лӘЁлӢү
- лҰ¬нҚј
- мҶҢмҡёмқҙн„°
- лҸ„нҷ”к°Җ
- кё°мғҒмҲ мӮ¬
(кө¬) мһҗлЈҢмҷҖ м •ліҙ
кіөнҶө м»Өл®ӨлӢҲнӢ°
- мҳӨн”Ҳ мқҙмҠҲ к°Өлҹ¬лҰ¬
- мҳӨлҠҳмқҳ н•«лІӨ
- мҳӨлҠҳмқҳ нҢҹлІӨ
- AI к·ёлҰј к·ёлҰ¬кё°
- PC кІ¬м Ғ кІҢмӢңнҢҗ
- мҪ”мҠӨн”„л Ҳ к°Өлҹ¬лҰ¬
- (19)л¬ҙмқёлҸ„лҠ” мІЁмқҙм§Җ?
- кІҢмқҙл°Қ мЈјліҖкё°кё°
- м§ҖлҰ„/к°ңлҙү к°Өлҹ¬лҰ¬
- кІҢмқҙлЁё нҶ лЎ мһҘ
- кІҢмһ„ 추мІң/мҶҢк°җ
- л¬ҙм—Үмқҙл“ л¬јм–ҙліҙм„ёмҡ”
- мөңк·ј л…јлһҖмӨ‘мқё мқҙм•јкё°
- лҚ”ліҙкё°
мқёкё° нҢҹлІӨ
- нҢҹлІӨ л°”лЎңк°Җкё°
- AI к·ёлҰј
- г„ҙAI к·ёлҰјк·ёлҰ¬кё°(л¶Җм—җлҘҙ)
- м• лӢҲл©”мқҙм…ҳ
- кұёк·ёлЈ№
- ліҙл“ңкІҢмһ„
- н…ҢмқјмҰҲмң„лІ„
- мІңм• лӘ…мӣ”лҸ„M
- мҶҢмҡёмӣҢм»Ө
- мҡҙлҸҷ
- мЈјмӢқ
- мқҙлӢҲл№ө
- D2R лӘ…н’ҲкҙҖ
- м№ҙмҠӨкёҖмҳө

|
2023-11-21 22:14
мЎ°нҡҢ: 228,853
추мІң: 447
мҙҲнҢҢкі ver.1.0 -мҷ„-м•Ҳл…•н•ҳм„ёмҡ”. мҙҲнҢҢкі к°ңл°ңмһҗ лЎңнҢҢкі мһ…лӢҲлӢӨ.
мҳӨлҠҳ мһҘк°‘ 7лӢЁкі„ м—…лҚ°мқҙнҠёлЎң мҙҲмӣ” л°©м–ҙкө¬ м „ л¶Җмң„ м „ лӢЁкі„мқҳ м—…лҚ°мқҙнҠёк°Җ лҒқлӮ¬мҠөлӢҲлӢӨ. 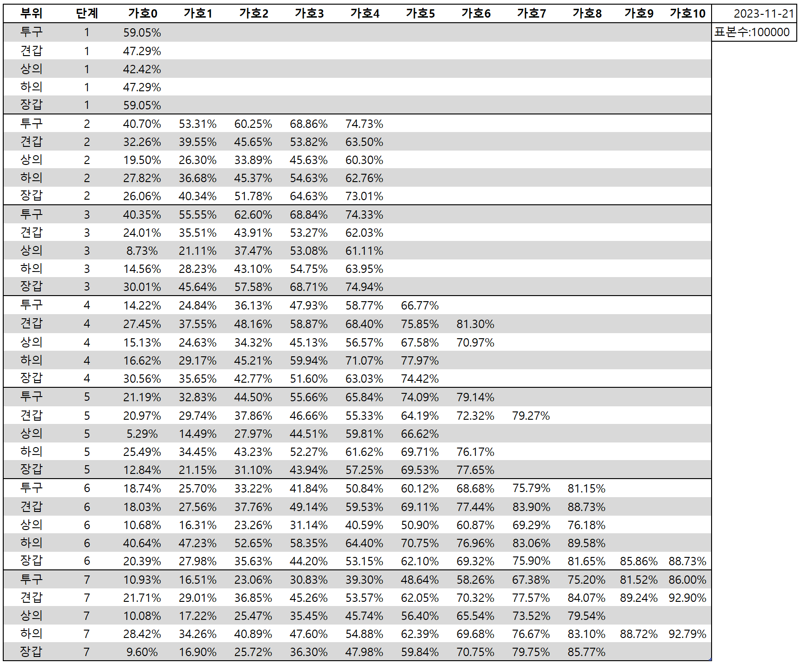  м ңк°Җ мҙҲмӣ” 1лӢЁкі„ лӘЁлҚё н•ҷмҠөмқ„ мӢңмһ‘н–ҲлҚҳ 10мӣ” 7мқјлЎңл¶Җн„°В 46мқјл§Ңм—җ лӘЁл“ лӘЁлҚё н•ҷмҠөмқ„ л§ҲміӨмҠөлӢҲлӢӨ. к·ёлҸҷм•Ҳ л§ҺмқҖ кҙҖмӢ¬ к°Җм ё мЈјмӢңкі лҠҗлҰ° н•ҷмҠө мӢңк°„мқ„ кё°лӢӨл Ө мЈјмӢ 분л“Өм—җкІҢ к°җмӮ¬л“ңлҰҪлӢҲлӢӨ. к·ё мҷё м§ңмһҳн•ң м—…лҚ°мқҙнҠёлӮҳ кё°лҠҘ 추к°ҖлҠ” мӣ№нҺҳмқҙм§Җмқҳ 'м—…лҚ°мқҙнҠё лЎңк·ё' л°Ҹ 'м„ӨлӘ…м„ң'лҘј м°ёмЎ°н•ҙмЈјмӢңл©ҙ к°җмӮ¬н•ҳкІ мҠөлӢҲлӢӨ. **** мһ¬лҜём—ҶлҠ” мһЎмҶҢлҰ¬ **** 1. мҙҲнҢҢкі м„ұлҠҘм—җ кҙҖн•ҙм„ң мҙҲнҢҢкі м„ұлҠҘмқҖ м ңк°Җ лҠҳ л§җм”Җл“ңлҰ¬м§Җл§Ң 'мөңкі мқҳ м„ұлҠҘ'мқҙ м•„лӢҲлқј 'м“ёл§Ңн•ң м„ұлҠҘ'к°Җ лӘ©н‘ңмһ…лӢҲлӢӨ. м„ұлҠҘм—җ кҙҖн•ҙм„ң м„ӨлӘ…мқ„ л“ңлҰ¬л Өл©ҙ мҡ°м„ н•ҷмҠө к·ёлһҳн”„лҘј лЁјм Җ м„ӨлӘ… л“ңлҰҙ н•„мҡ”к°Җ мһҲмҠөлӢҲлӢӨ. лӢӨмқҢмқҖ нҲ¬кө¬ 6лӢЁкі„ мҙҲмӣ” н•ҷмҠө к·ёлһҳн”„ мӨ‘ мҙҲл°ҳ мқјл¶Җмһ…лӢҲлӢӨ. (н•ҷмҠөмқ„ мң„н•ҙ мқјл¶Җлҹ¬ нӣЁм”¬ мү¬мҡҙ м—ҳмЎ°мңҲ 8лӢЁкі„л¶Җн„° мӢңмһ‘н•ң кІғмқҙлқј мӢӨм ң м„ұлҠҘкіјлҠ” м°Ёмқҙк°Җ мһҲмҠөлӢҲлӢӨ.) 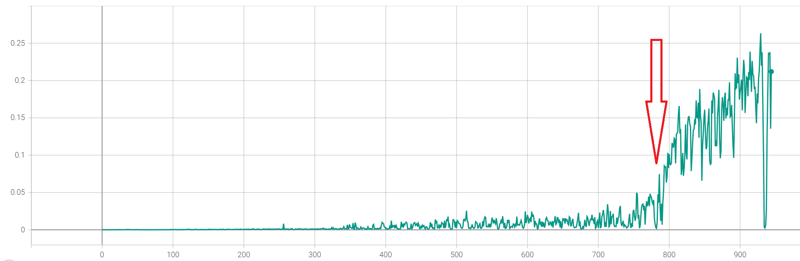 м„ёлЎң축мқҖ 3м„ұ лӢ¬м„ұ нҷ•лҘ , к°ҖлЎң 축мқҖ н•ҷмҠө нҡҹмҲҳлҘј мқҳлҜён•©лӢҲлӢӨ. м•Ҫ 400нҡҢк№Ңм§ҖлҠ” 3м„ұ лӢ¬м„ұлҘ мқҙ 1%лҸ„ лҗҳм§Җ м•ҠлӢӨк°Җ, лҳҗ лӢӨмӢң мқҙм–ҙм§ҖлҠ” 380нҡҢ м •лҸ„лҠ” 2~3%лҢҖм—җм„ң м „нҳҖ м„ұлҠҘмқҙ мҳӨлҘҙм§Җ м•ҠлҠ” лӘЁмҠөмқ„ ліҙмһ…лӢҲлӢӨ. к·ёлҹ¬лӢӨк°Җ м•Ҫ 780нҡҢ мҜӨм—җ 5%мқҳ лІҪмқ„ лҡ«кі , м•Ҫ 150нҡҢ л§Ңм—җ м„ұлҠҘмқҙ 20% л„ҳкІҢ м№ҳмҶҹлҠ” кІғмқ„ ліҙмӢӨ мҲҳ мһҲмҠөлӢҲлӢӨ. мқҙнӣ„м—җлҠ” м„ұлҠҘ к°ңм„ мҶҚлҸ„к°Җ м җм җ лҠҗл Ө집лӢҲлӢӨ.  мқҙ к·ёлһҳн”„лҠ” мң„мқҳ нҲ¬кө¬ 6лӢЁкі„ м—ҳмЎ°мңҲ 8лӢЁкі„лҘј кі„мҶҚн•ҙм„ң 3лІҲм—җ лӮҳлҲ„м–ҙ 진н–үн•ң мҙқ м•Ҫ 105мӢңк°„мқҳ н•ҷмҠө к·ёлһҳн”„мһ…лӢҲлӢӨ. нӣ„л°ҳл¶ҖлЎң к°Җл©ҙ к°Ҳ мҲҳлЎқ м җм җ н•ҷмҠө мҶҚлҸ„к°Җ лҠҗл Өм§ҖкІҢ лҗ©лӢҲлӢӨ. мқҙ 'мІңмІңнһҲ мҳӨлҘҙлҠ”' кө¬к°„м—җм„ңлҠ” м—¬лҹ¬л¶„л“Өмқҙ нқ”нһҲ л§җн•ҳлҠ” 'мҙҲнҢҢкі к°Җ кі мһҘлӮ¬лӢӨ' н•ҳлҠ” л¶Җ분л“Өмқҙ н•ҳлӮҳм”© кі міҗм§ҖлҠ” кіјм •мһ…лӢҲлӢӨ. мҙҲл°ҳм—җм•ј 12мӢңк°„л§Ңм—җ 10% м„ұлҠҘмқҙ 36%к№Ңм§Җ мғҒмҠ№н• м •лҸ„лЎң кёүкІ©н•ҳкІҢ м„ұлҠҘ н–ҘмғҒмқҙ мһҲкё° л•Ңл¬ём—җ мӢңк°„кіј м—°мӮ°л Ҙмқ„ нҲ¬мһҗн• к°Җм№ҳк°Җ мһҲм§Җл§Ң, нӣ„л°ҳмңјлЎң к°Җл©ҙ 12мӢңк°„лҸҷм•Ҳ 74% м„ұлҠҘмқҙ 76%лЎң кё°к»Ҹн•ҙм•ј 2~3%p мғҒмҠ№н•ҳлҠ” кІғмқҙ кі мһ‘мқҙкё° л•Ңл¬ём—җ нҲ¬мһҗн• к°Җм№ҳк°Җ нҒ¬кІҢ мӨ„м–ҙл“ӯлӢҲлӢӨ. л”°лқјм„ң м„ұлҠҘкіјмқҳ нғҖнҳ‘мқҙ л¶Ҳк°Җн”јн•©лӢҲлӢӨ. лҳҗ н•ҳлӮҳ, м„ұлҠҘмқ„ нғҖнҳ‘н•ҙм•ј н•ҳлҠ” мқҙмң лҠ” лӘЁлҚёмқҳ нҒ¬кё°мҷҖлҸ„ кҙҖл Ёмқҙ мһҲмҠөлӢҲлӢӨ. нҳ„мһ¬ мҙҲнҢҢкі мқҳ нҷ•лҘ мқ„ кі„мӮ°н•ҳлҠ” кі„мӮ° лӢҙлӢ№ лӘЁлҚёмқҳ кІҪмҡ°, 1~5лӢЁкі„лҠ” м•Ҫ 5MB нҒ¬кё°мқҙл©°, 6,7лӢЁкі„лҠ” мЎ°кёҲ лҚ” нҒ° 6.5MBмқҳ нҒ¬кё°мһ…лӢҲлӢӨ. мқҙкІҢ м–ҙлҠҗ м •лҸ„лЎң мһ‘мқҖ лӘЁлҚёмқём§Җ 비көҗлҘј н•ҙл“ңлҰ¬мһҗл©ҙ,В нҳ„мһ¬ к°ҖмһҘ м„ұлҠҘ л¶Ҳл§Ңмқҙ л§ҺмқҖ нғҖмқј мқёмӢқ лӘЁлҚёмқҳ кІҪмҡ° 16MB мқҙл©°, л”Ҙлҹ¬лӢқмқҙ м•„лӢҢ лӢЁмҲң н…Ңмқҙлё” л°©мӢқмқ„ мӮ¬мҡ©н•ң м—ҳнҢҢкі мқҳ кІҪмҡ° 비м ҖкІ©, м ҖкІ©лӘЁл“ң м „мІҙ н•©міҗм„ң м•Ҫ 20GBмқҳ мҡ©лҹүмқ„ м°Ём§Җн•©лӢҲлӢӨ. л¬јлЎ к°•нҷ”н•ҷмҠө(Reinforcement Learning)м—җм„ң лӘЁлҚёмқҳ нҒ¬кё°лҠ” лӢӨлҘё л”Ҙлҹ¬лӢқ 분야м—җ 비н•ҙ мӨ‘мҡ”лҸ„к°Җ л§Һмқҙ л–Ём–ҙм§Җм§Җл§Ң, мҙҲмӣ”мқҙлӮҳ м—ҳлҰӯм„ңмҷҖ к°ҷмқҖ кІҪмҡ°лҠ” 'лӮңмқҙлҸ„'к°Җ м–ҙл өлӢӨкё° ліҙлӢӨлҠ” 'к°Җ짓мҲҳ'к°Җ л§ҺмқҖ кІҪмҡ°мқҙкё° л•Ңл¬ём—җ 'мөңкі м җ'мқҳ м„ұлҠҘмқ„ л…ёлҰ°лӢӨл©ҙ лӘЁлҚё нҒ¬кё°к°Җ мҳҒн–Ҙмқ„ мӨ„ мҲҳл°–м—җ м—ҶмҠөлӢҲлӢӨ. лӘЁлҚё нҒ¬кё°лҘј нӮӨмҡ°л©ҙ лӢӨмқҢ 3к°Җм§Җ л¬ём ңк°Җ л°ңмғқн•©лӢҲлӢӨ. 1. н•ҷмҠө мӢңк°„мқҙ лҢҖнҸӯ мҰқк°Җн•©лӢҲлӢӨ. 2. лёҢлқјмҡ°м Җм—җм„ң лҸҢлҰ¬кё° л•Ңл¬ём—җ мқҙмҡ©мһҗмқё м—¬лҹ¬л¶„л“Өмқҳ лёҢлқјмҡ°м Җ л°Ҹ м»ҙн“Ён„° м„ұлҠҘм—җ л”°лқј к·№мӢ¬н•ң м„ұлҠҘ м Җн•ҳк°Җ л°ңмғқн• м—¬м§Җк°Җ мһҲмҠөлӢҲлӢӨ. м§ҖкёҲ лӘЁлҚёлЎңлҸ„ н•ңлІҲ кі„мӮ°м—җ 1мҙҲ мқҙмғҒ кұёлҰ¬мӢңлҠ” 분л“ӨлҸ„ кі„мӢ кІғмңјлЎң м•Ңкі мһҲкё° л•Ңл¬ём—җ л¬ҙмӢңн• мҲҳ м—ҶлҠ” л¬ём ңмһ…лӢҲлӢӨ. 3. л„ӨнҠёмӣҢнҒ¬ нҠёлһҳн”Ҫмқҙ лҢҖнҸӯ мҰқк°Җн•©лӢҲлӢӨ. м—ҳнҢҢкі к№Ңм§Җл§Ң н•ҙлҸ„ мқҙмҡ©мһҗк°Җ мқј мҲҳл°ұлӘ… мҲҳмӨҖмқҙм–ҙм„ң кө¬кёҖ нҒҙлқјмҡ°л“ң кё°ліё л¬ҙлЈҢ м ңкіө мҲҳмӨҖм—җм„ң н•ҙкІ°лҗҳм—ҲмҠөлӢҲлӢӨл§Ң, нҳ„мһ¬лҠ” мөңк·ј 30мқјк°„ м•Ҫ 300GBлЎң м „мІҙ мҡ”кёҲмқҳ м•Ҫ 1/3 к°Җлҹүмқ„ м°Ём§Җн• м •лҸ„лЎң лҠҳм—ҲмҠөлӢҲлӢӨ. к·ёлӮҳл§ҲлҸ„ нҒҙлқјмҡ°л“ң н”Ңл Ҳм–ҙ нҶөкі„мғҒ 6TB м •лҸ„к°Җ мәҗмӢңлЎң м ңкіөлҗң мғҒнғңмһ…лӢҲлӢӨ. 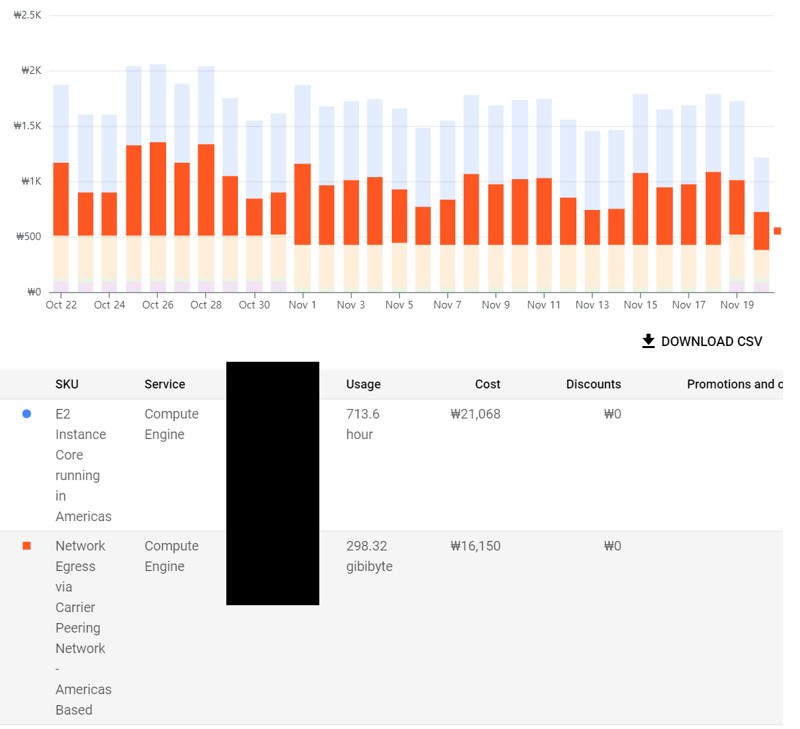  2~3л°° м •лҸ„л©ҙ нҒ¬кІҢ мғҒкҙҖм—ҶкІ м§Җл§Ң, нҳ„мӢӨм ҒмңјлЎң мң мқҳлҜён•ң м„ұлҠҘ кі м җмқ„ л°”лқјліёлӢӨл©ҙ лӘЁлҚё нҒ¬кё°лҘј мөңмҶҢ 10л°°м •лҸ„лҠ” нӮӨмӣҢм•ј мқҳлҜёк°Җ мһҲлҠ”лҚ°, лҸҲмқҖ л‘ҳм§ё м№ҳкі м—¬лҹ¬л¶„л“Ө лӢӨмҡҙлЎңл“ң мӢңк°„мқ„ нҸ¬н•Ён•ҙм„ң мӣ№мӮ¬мқҙнҠёк°Җ нӣЁм”¬ лҠҗл Өм§Ҳ к°ҖлҠҘм„ұмқҙ лҶ’мҠөлӢҲлӢӨ.В мқҙлҹ¬н•ң м ңм•Ҫ мӮ¬н•ӯл“Өмқ„ л”°м ёлҙӨмқ„ л•Ң, м„ұлҠҘм—җ нғҖнҳ‘мқ„ н•ҳлҠ” кІғмқҙ л§һлӢӨлҠ” мғқк°Ғмқҙ л“Өм–ҙ нҳ„мһ¬ лӘЁлҚё м„ұлҠҘмқ„ мң м§Җн•ҳкё°лЎң кІ°м •н–ҲмҠөлӢҲлӢӨ. 2. мҙҲнҢҢкі мқҳ м—ӯн• кіөмӢқм Ғмқё м ң мһ…мһҘмқҖ, мҙҲнҢҢкі мқҳ м„ұлҠҘмқҖ мӮ¬лһҢліҙлӢӨ лӮ«м§Җ м•ҠлӢӨ мһ…лӢҲлӢӨ. к·ёлҹј мҷң м“°лҠҗлғҗ? мҙҲнҢҢкі мқҳ м—ӯн• мқҖ м—¬лҹ¬л¶„л“Өм—җкІҢ 'м•Ҳм „л§қ'мқ„ м ңкіөн•ҳлҠ” кІғмһ…лӢҲлӢӨ. мҙҲмӣ” 7лӢЁкі„ кІ¬к°‘ м—ҳмЎ°мңҲ 0лӢЁкі„лҘј мҳҲлЎң л“Өмһҗл©ҙ, мҙҲнҢҢкі лҠ”В мҙҲмЎё, мӨ‘мЎё, кі мЎё, лҢҖмЎё, мІҷмІҷм„қмӮ¬, мІҷмІҷл°•мӮ¬ м•„л¬ҙ мғҒкҙҖ м—Ҷмқҙ м•Ҫ 21.71%мқҳ нҷ•лҘ лЎң 3м„ұ лӢ¬м„ұн•ҳлҠ” л°©лІ•мқ„ м•Ңл Өл“ңлҰҪлӢҲлӢӨ. мң„ н‘ңмқҳ 21.71%лҠ” м—¬лҹ¬л¶„л“Өмқҙ нқ”нһҲ л§җм”Җн•ҳмӢңлҠ” 'мҙҲнҢҢкі к°Җ нӣ„л°ҳ к°ҖлӢҲ кі мһҘлӮ¬лӢӨ' лқјкі н•ҳлҠ” мғҒнҷ©мқ„ лӘЁл‘җ нҸ¬н•Ён•ҙм„ң 10л§Ң лІҲмқҳ мҙҲмӣ”мқ„ 진н–ү н–Ҳмқ„ л•Ң м•Ҫ 2л§Ң лІҲмқҙ 3м„ұмқ„ лӢ¬м„ұн–ҲлӢӨлҠ” лң»мһ…лӢҲлӢӨ. мҰү, мҙҲнҢҢкі к°Җ 100% нҷ•лҘ лЎң мҷңкіЎ 3к°ңлҘј л¶ҖмҲҳлқјкі мӢңнӮӨкұҙ, мһ¬л°°м№ҳлҘј л¶ҖмҲҳлқјкі мӢңнӮӨкұҙ м•„~л¬ҙ мқҳмӢ¬ м—Ҷмқҙ л¬ҙмһ‘м • л”°лқјлҸ„ 100лІҲ мҙҲмӣ” 진н–үн•ҳл©ҙ нҸүк· м ҒмңјлЎң 21лІҲмқҖ 3м„ұм—җ лҸ„лӢ¬н•ңлӢӨлҠ” мқҳлҜёмһ…лӢҲлӢӨ. м—¬лҹ¬л¶„мқҙ лҚ” мһҳ к№ҺмңјмӢӨ мһҗмӢ мқҙ мһҲкұ°лӮҳ, мҙҲнҢҢкі мқҳ 추мІңмқҙ мһҳлӘ»лҗҳм—ҲлӢӨкі мғқк°Ғн•ҳмӢ лӢӨл©ҙ лӢ№м—°нһҲ м—¬лҹ¬л¶„мқҳ м„ нғқмқ„ л”°лҘҙлҠ” кІғмқҙ л§һмҠөлӢҲлӢӨ.В 'мҙҲнҢҢкі лҘј л”°лҘҙм§Җ м•Ҡмңјл©ҙ л§қн•ңлӢӨ' к°Җ м•„лӢҲлқј, 'м„ нғқмқ„ лӘ» н• л•Ң мҙҲнҢҢкі лҘј л”°лқјк°Җл©ҙ мөңмҶҢн•ң мҙҲнҢҢкі л§ҢнҒјмқҖ н• мҲҳ мһҲлӢӨ' мһ…лӢҲлӢӨ. нҠ№нһҲ 'нӣ„л°ҳл¶Җм—җ к°Җл©ҙ мҙҲнҢҢкі к°Җ кі мһҘлӮңлӢӨ' лқјлҠ” л§җмқҖ л°ҳмқҖ л§һкі л°ҳмқҖ нӢҖлҰҪлӢҲлӢӨ. мўҖ м •нҷ•н•ң н‘ңнҳ„мқҖ 'нӣ„л°ҳл¶Җм—җ к°Җл©ҙ мҙҲнҢҢкі к°Җ кі мһҘлӮң кІғмқ„ м•Ңм•„м°ЁлҰҙ мҲҳ мһҲлӢӨ' мһ…лӢҲлӢӨ. мғҒмқҳ 1~5лӢЁкі„мІҳлҹј к·№лӢЁм ҒмңјлЎң нҡҹмҲҳк°Җ м ҒмқҖкІҢ м•„лӢҢ мқҙмғҒ, мҲҳн•ҷм ҒмңјлЎң лҙӨмқ„ л•Ң кІҪмҡ°мқҳ мҲҳ мһҗмІҙлҠ” нӣ„л°ҳл¶Җ ліҙлӢӨ мӨ‘л°ҳл¶Җк°Җ лҚ” л§ҺмҠөлӢҲлӢӨ. мҰү, мҙҲнҢҢкі к°Җ м—үлҡұн•ң мЎ°м–ёмқ„ мӨ‘л°ҳл¶Җм—җ н• к°ҖлҠҘм„ұлҸ„ мғҒлӢ№нһҲ лҶ’мҠөлӢҲлӢӨ. н•ҳм§Җл§Ң мӨ‘л°ҳл¶Җм—җм„ңлҠ” лӯ”к°Җ мһҳлӘ»лҗң кІғ к°ҷмқҖ 'лҠҗлӮҢ'мқҖ мһҲм–ҙлҸ„ мҰқлӘ…н• мҲҳлҠ” м—Ҷкі , нӣ„л°ҳл¶Җм—җм„ңлҠ” мӢӨм ңлЎң нҷ•лҘ мқ„ мҲҳн•ҷм ҒмңјлЎң кі„мӮ° к°ҖлҠҘн•ҳлӢӨлҠ” м°Ёмқҙм җ л•Ңл¬ём—җ нӣ„л°ҳл¶Җм—җ нҠ№нһҲ кі мһҘмқҙ л§Һмқҙ лӮңлӢӨкі лҠҗлҒјмӢӨ мҲҳ мһҲмҠөлӢҲлӢӨ. л”°лқјм„ң мҙҲнҢҢкі лҘј 'кІҪмҹҒ мғҒлҢҖ' ліҙлӢӨлҠ” 'мЎ°мҲҳ' м •лҸ„лЎңл§Ң мғқк°Ғн•ҙ мЈјмӢңкё° л°”лһҚлӢҲлӢӨ. к°Җм„ұ비лқјлҠ” к°ңл…җмқҙ л“Өм–ҙк°ҖлҠ” мҲңк°„ AIлҠ” к·јліём ҒмңјлЎң мӮ¬лһҢмқ„ мқҙкё°кё° м–ҙл өмҠөлӢҲлӢӨ. мқёк°„л§ҢнҒј м„ұлҠҘ лҢҖ비 м Җл ҙн•ң кІғлҸ„ м—Ҷкё° л•Ңл¬ёмһ…лӢҲлӢӨ. лҢҖкё°м—… AIлҸ„ мқҙ л¬ём ңм—җм„ң лІ—м–ҙлӮҳм§Җ лӘ»н•ҳлҠ”лҚ°, н•ҳл¬јл©° л¬ҙлЈҢлЎң м ңкіөн•ҳлҠ” м ң мҙҲнҢҢкі к°Җ м—¬лҹ¬л¶„ліҙлӢӨ лӮҳмқ„ мҲҳ м—ҶмҠөлӢҲлӢӨ. 3. мҙҲнҢҢкі мҪ”л“ң кҙҖн•ҙм„ң кІ°лЎ л¶Җн„° л§җм”Җл“ңлҰ¬л©ҙ, н”„лЎ нҠём—”л“ңлҘј нҸ¬н•Ён•ҙм„ң мҙҲнҢҢкі мқҳ лӘЁл“ мҪ”л“ңлҠ” кіөк°ңн•ҳм§Җ м•ҠмҠөлӢҲлӢӨ. нҠ№нһҲ н•ҷмҠө нҷҳкІҪ, м„ёнҢ…, лӘЁлҚё мў…лҘҳ л“ұм—җ кҙҖн•ҙм„ңлҸ„ мқјмІҙ кіөк°ңн•ҳм§Җ м•Ҡмқ„ мҳҲм •мқҙлӢҲ, лҚ” мқҙмғҒ л¬ёмқҳ мЈјмӢңм§Җ м•Ҡмңјм…Ёмңјл©ҙ мўӢкІ мҠөлӢҲлӢӨ. м ңкІҢ мҪ”л“ң кҙҖн•ҙм„ң м—°лқҪ мЈјмӢңлҠ” 분л“ӨмқҖ нҒ¬кІҢ л‘җ л¶ҖлҘҳлЎң лӮҳлү©лӢҲлӢӨ. 1. н”„лЎ нҠём—”л“ң к°ңл°ң нҳ‘л Ҙ л¬ёмқҳ 2. мҙҲнҢҢкі н•ҷмҠө м„ёнҢ… л¬ёмқҳ мІ«лІҲм§ё 분л“ӨмқҖ кіөнҶөм ҒмңјлЎң ліёмқёмқҙ м–ҙл–Ө мӮ¬лһҢмқём§Җ, м–ҙл–Ө кё°мҲ мқҙ мһҲлҠ”м§Җ, м–ҙл–Ө лҸ„мӣҖмқ„ мӨ„ мҲҳ мһҲлҠ”м§Җ мһҗм„ён•ҳкІҢ л§җм”Җн•ҙ мЈјмӢңл©ҙм„ң н”„лЎ нҠём—”л“ң к°ңл°ңм—җ лҸ„мӣҖмқ„ мЈјкі мӢ¶лӢӨлҠ” м—°лқҪмқ„ мЈјмӢӯлӢҲлӢӨ. м •л§җ к°җмӮ¬н•ң м—°лқҪмһ…лӢҲлӢӨл§Ң, н”„лЎ нҠём—”л“ң к°ңл°ңмқҖ м „л¬ёк°Җ 분мңјлЎңл¶Җн„° мқҙлҜё мЎ°м–ёмқ„ л°ӣкі мһҲкё° л•Ңл¬ём—җ м •мӨ‘н•ҳкІҢ кұ°м Ҳн–ҲмҠөлӢҲлӢӨ. л‘җлІҲм§ё м—°лқҪмқҳ кІҪмҡ° лӢЁ н•ңлІҲлҸ„ м–ҙл–Ө мӮ¬лһҢмқём§Җ, м–ҙл–Ө м—°кө¬лҘј н–ҲлҠ”м§Җ, нҳ№мқҖ м–ҙл–Ө лҸ„мӣҖмқ„ мӨ„ мҲҳ мһҲлҠ”м§Җ л§җм”Җ мЈјмӢ 분мқҙ м—Ҷм—Ҳкі , н•ҷмҠө м„ёнҢ…кіј лӘЁлҚё, л°©лІ•м—җ лҢҖн•ҙм„ң м§Ҳл¬ёл§Ң мЈјм…ЁмҠөлӢҲлӢӨ. м ңк°Җ лӘЁмқҖ лҚ°мқҙн„°лҠ” лӘЁл‘җ мқёкІҢмһ„ лӮҙм—җм„ң м–»мқ„ мҲҳ мһҲлҠ” м •ліҙмһ…лӢҲлӢӨ. мҠӨмҠӨлЎң 충분нһҲ лӘЁмқ„ мҲҳ мһҲлҠ” м •ліҙлҘј м•„л¬ҙлҹ° л§ҘлқҪлҸ„ м—Ҷмқҙ мҡ”кө¬н•ҳлҠ” кІғмқҖ лҢҖлӢЁнһҲ л¬ҙлЎҖн•ң н–үлҸҷмһ…лӢҲлӢӨ.В м„ңлІ„ ліҙм•Ҳ мёЎл©ҙм—җм„ңлҸ„ мҪ”л“ң кіөмң к°Җ м–ҙл Өмҡ°лӢҲ, мҪ”л“ң кіөк°ң/кіөмң кҙҖл Ё л¬ёмқҳлҠ” л°ӣм§Җ м•ҠмҠөлӢҲлӢӨ. м–‘н•ҙ л¶ҖнғҒл“ңлҰҪлӢҲлӢӨ. ***************** мҙҲнҢҢкі м—җ л§ҺмқҖ кҙҖмӢ¬ мЈјмӢ кІғ лӢӨмӢң н•ң лІҲ к°җмӮ¬л“ңлҰҪлӢҲлӢӨ. мқҙнӣ„ 진н–ү л°©н–ҘмқҖ нҷ”л©ҙмқёмӢқ к°ңм„ мқ„ н• м§Җ, м—ҳнҢҢкі к°ңм„ мқ„ н• м§ҖлҠ” м•„м§Ғ лҜём§ҖмҲҳмһ…лӢҲлӢӨл§Ң, мөңмҶҢн•ң мҙҲмӣ”/м—ҳлҰӯм„ң к°ҷмқҖ м“°л Ҳкё° к°•нҷ”мӢңмҠӨн…ңмқҙ лҳҗ лӮҳмҷҖм„ң лҳҗ лӢӨлҘё нҢҢкі мӢңлҰ¬мҰҲлҘј л§Ңл“Ө мқјмқҙ м—Ҷм—Ҳмңјл©ҙ мўӢкІ мҠөлӢҲлӢӨ. нҳңмһҗкі м°Ҫл ¬мқҙкі мғҒкҙҖ м—Ҷмқҙ лҸҲ л“Өм–ҙк°ҖлҠ” к°•нҷ” мӢңмҠӨн…ңм—җ нҷ•лҘ к°Җм§Җкі мһҘлӮңм№ҳлҠ” м—ӯкІЁмҡҙ 짓мқ„ мўҖ к·ёл§Ң лҙӨмңјл©ҙ н•ҳлҠ” л°”лһҢмқҙ мһҲмҠөлӢҲлӢӨ. к°җмӮ¬н•©лӢҲлӢӨ.
EXP
3,832
(57%)
/ 4,001
|
 лЎңнҢҢкі
лЎңнҢҢкі |
|
м§ҖкёҲ лңЁлҠ” н•«лІӨ
лҚ”ліҙкё°+м§ҖкёҲ лңЁлҠ” нҢҹлІӨ
лҚ”ліҙкё°+лЎңмҠӨнҠём•„нҒ¬ мқёлІӨ мһҗмң кІҢмӢңнҢҗ(кө¬) кІҢмӢңнҢҗ
мқёлІӨ м „кҙ‘нҢҗ
[лҰҙлҰ¬м•„м•„лҰ°] г…Үг……г…Ү
[мһҗкё°кі„л°ңн•ҙ] лЎңмҠӨнҠём•„нҒ¬ = м°Ём„ёлҢҖ лҰ¬лӢҲм§Җ
[Ezikial] мӮ¬л©ёмқҳ мҷ•, м Ҳм ңк°Җ л“ңл””м–ҙ н•ҳлҠҳм—җ мқҙлҘҙл ҖлӢӨ.
лЎңм•„ мқёлІӨ м „кҙ‘нҢҗ мӢңмһ‘!!
[л°”л“ңнһҗл§Ғ] л¶ҲкёҲм—” г…Үг……г…Үн•ҳлҠ” мӮ¬лһҢ м—Ҷм–ҙм„ң мўӢл„Ө
[лҚ”мӣҢмҡ”33] л¬ҙм Ғ007мқҖ мӢ мқҙлӢӨ
[Arbok] м•„мқҙм–ҙлҠ” л¶Җнҷңн• кІғмқҙлӢӨ.
[лҚ”мӣҢмҡ”33] л¬ҙм Ғ007мқҖ л¶Җнҷңн• кІғмқҙлӢӨ