









IT인벤 뉴스와 정보
IT 인벤 커뮤니티
공통 커뮤니티
- 오픈 이슈 갤러리
- 오늘의 핫벤
- 오늘의 팟벤
- AI 그림 그리기
- PC 견적 게시판
- 코스프레 갤러리
- (19)무인도는 첨이지?
- 게이밍 주변기기
- 지름/개봉 갤러리
- 게이머 토론장
- 게임 추천/소감
- 무엇이든 물어보세요
- 최근 논란중인 이야기
- 더보기
인기 팟벤

|
2024-03-19 14:21
조회: 772
추천: 0
NASA의 오래된 슈퍼컴퓨터로 인해 임무 지연이 발생하고 있습니다. 하나는 CPU가 18,000개인데 GPU가 48개에 불과해 업데이트가 절실히 필요합니다.기사 원문 - https://www.tomshardware.com/tech-industry/supercomputers/nasas-old-supercomputers-are-causing-mission-delays
 NASA는 세계에서 가장 진보된 기술을 활용하여 인류 역사상 가장 중요한 발견을 이루어냈습니다. 그러나 NASA 감찰실이 실시하고 The Register가 발견한 특별 보고서 에 따르면 NASA의 슈퍼컴퓨팅 능력이 해당 작업을 수행하기에 부족하여 임무 지연으로 이어진다고 합니다. NASA의 슈퍼컴퓨터는 여전히 주로 CPU에 의존하고 있으며, 주요 슈퍼컴퓨터 중 하나는 18,000개의 CPU와 48개의 GPU를 사용합니다. NASA는 현재 캘리포니아주 에임스에 있는 NASA 고급 슈퍼컴퓨팅(NAS) 시설과 메릴랜드주 고다드에 있는 NASA 기후 시뮬레이션 센터(NCCS)에 5개의 중앙 고급 컴퓨팅(HEC) 자산을 보유하고 있습니다. 목록에는 Aitken(13.12 PFLOPS, 인간을 달로 돌려보내고 그곳에 지속 가능한 존재를 구축하는 것을 목표로 하는 Artemis 프로그램을 지원하도록 설계됨), Electra(8.32 PFLOPS), Discover(8.1 PFLOPS, 기후 및 날씨 모델링에 사용됨), 플레이아데스(7.09 TFLOPS, 기후 시뮬레이션, 천체 물리학 연구, 항공우주 모델링에 사용됨)와 엔데버(154.8 TFLOPS). 이러한 시스템은 거의 독점적으로 오래된 CPU 코어를 사용합니다. 예를 들어, 모든 NAS 슈퍼컴퓨터는 18,000개 이상의 CPU와 48개의 GPU만 사용하며, NCSS는 훨씬 더 적은 수의 GPU를 사용합니다. 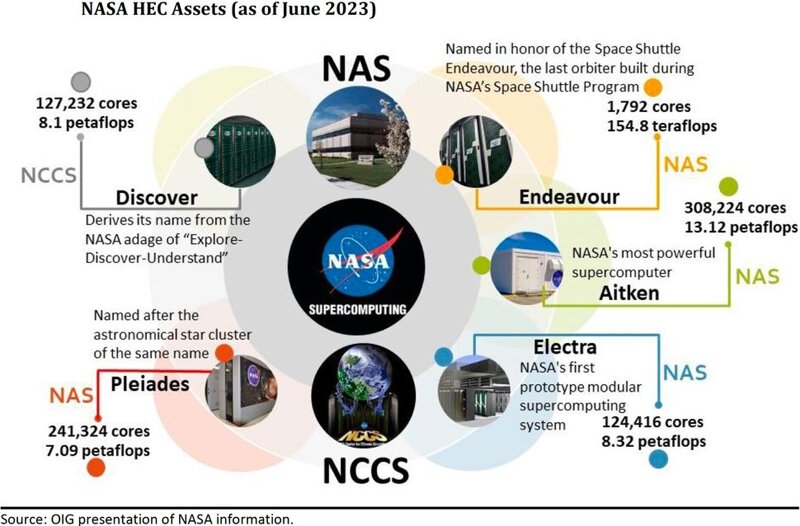 "HEC 관계자는 NASA의 시스템을 현대화할 수 없는 것은 공급망 문제, 최신 컴퓨팅 언어(코딩) 요구 사항, 새로운 기술을 구현하는 데 필요한 자격을 갖춘 인력의 부족 등 다양한 요인에 기인할 수 있다고 말하면서 이번 관찰과 관련하여 여러 가지 우려를 제기했습니다. "라고 보고서는 말합니다. "궁극적으로 현재 HEC 인프라를 현대화할 수 없는 것은 기관의 탐사, 과학 및 연구 목표를 달성하는 능력에 직접적인 영향을 미칠 것입니다." NASA 감찰실이 실시한 감사에서는 기관의 HEC 운영이 중앙에서 관리되지 않아 비효율성이 발생하고 온프레미스 대 클라우드 컴퓨팅 리소스 사용에 대한 응집력 있는 전략이 부족하다는 사실도 밝혀졌습니다. 이러한 불확실성으로 인해 알 수 없는 일정 관리 방식이나 더 높은 비용이 발생할 것으로 예상되어 클라우드 리소스 사용을 주저하게 되었습니다. 일부 임무에서는 기본 슈퍼컴퓨팅 리소스에 대한 액세스를 기다리지 않기 위해 인프라 확보에 의존했는데, 이는 최신 HPC 기술에 의존하지 않기 때문에 상당한 수준으로 압도됩니다. 또한 감사에서는 HEC 인프라에 대한 보안 통제가 종종 우회되거나 구현되지 않아 사이버 공격의 위험이 증가한다는 사실을 발견했습니다. 보고서는 GPU로의 전환과 코드 현대화가 NASA의 현재와 미래 요구 사항을 충족하는 데 필수적이라고 제안합니다. GPU는 과학 시뮬레이션 및 모델링에서 매우 일반적인 병렬 처리와 관련된 워크로드에 대해 훨씬 더 높은 계산 기능을 제공합니다.
EXP
92,837
(16%)
/ 97,001
|
 Bector
Bector